
Deep Reinforcement Learning: A New Frontier for Robotic Arms
In robotics, programming a machine how to move and manipulate objects used to rely heavily on hand-coded instructions. Engineers had to carefully tune sensor thresholds, define joint movements, and anticipate every possible situation a robot might face. This rule-based approach works well for simple, repetitive tasks in controlled environments, but it quickly breaks down when robots encounter the unpredictable nature of the real world.
Today, as industries like automotive, manufacturing, and electronics assembly push for higher automation, robots are increasingly expected to handle complex, unstructured tasks. These challenges cannot be fully captured through fixed instructions or even traditional sequential programming, where each action is executed without considering the outcome of the previous one. Consider the task of handling cables: they are soft, flexible, and capable of twisting into countless shapes. Their behavior changes every time, making it nearly impossible to control them with rigid, predefined rules.
This shift in expectations reveals a deeper truth: solving hard robotics problems isn’t just about inventing better algorithms. The algorithm is only one piece. To operate well in complex tasks, robots need software architectures that support rapid experimentation, iteration, realtime adaptation and integration of different forms of intelligence. A strong foundation becomes just as important as the algorithm that runs on top of it.
In recent years, deep RL has emerged as a game-changer in robotic control. Instead of programming a robot arm’s motions line by line, we define a goal (through a reward function) and allow the robot to figure out how to achieve it through trial and error. It’s akin to how one might teach a child a new skill: provide feedback on good vs. bad outcomes and let them improve over many attempts. By running countless simulated trials, a deep neural network controller can gradually discover an effective strategy, whether it’s balancing a two-legged robot, picking up a delicate object, or precisely inserting a peg in a hole, all without a human writing those instructions in code directly.
Gearbox assembly powered by AICA System at Schaeffler’s facility
This learning-first approach isn’t just an academic concept, it’s already delivering impressive results in both simulation and the real world. One well-known example comes from OpenAI, where researchers trained a robotic hand to manipulate objects with remarkable dexterity, even solving a Rubik’s Cube and it did all of this by practicing entirely in simulation. The key was a technique called domain randomization, where the virtual environment was constantly changed, varying object weights, surface frictions, lighting, textures, and more. This forced the robot to learn general strategies that would still work when transferred to the real world, treating it as just another variation it had already seen.
On the industrial side, reinforcement learning has shown its strength in complex, high-precision tasks. In one case, a learning-based system mastered inserting gears into a dense gearbox assembly, something traditionally considered too delicate for automation. Not only did it succeed, but it cut cycle time by more than 30% compared to a manually programmed solution, all without needing highly specialized robotics code.
These breakthroughs hint at a powerful shift: when robots are allowed to learn from experience, they can discover solutions that human engineers might not think to program at all. But does this mean we can just train everything in simulation and call it a day? Not quite. One recurring challenge is the notorious sim-to-real gap, the gulf between the perfect, convenient world of a simulator and the messy complexities of reality. A policy that performs flawlessly in simulation can still fail in the real world, sometimes due to something as subtle as a slight change in surface friction or unexpected glare on a camera lens.
Deep reinforcement learning is famously data-hungry, often requiring millions of trial-and-error interactions to learn a task. Running that many trials on a physical robot isn’t practical, it would take weeks, wear down hardware, and burn through resources. That’s why most training happens in simulation, where data is cheap, fast, and safe to collect.
Of course, simulations are never perfect. Even small mismatches between simulated and real-world physics, like slight changes in friction or lighting, can cause learned behaviors to fail once deployed. This sim-to-real gap remains a major hurdle in robotics. To close it, engineers enhance simulator realism by tuning physics parameters and use techniques like domain randomization and actuator dynamics modelling to train policies that can handle real-world unpredictability.
Even when a policy works, understanding how it works can be tricky. Neural network controllers may be effective, but they often lack transparency. It’s difficult to know why a robot made a particular decision or how to adjust its behavior. As a result, many companies take a conservative approach: once a deep RL policy is trained, they “lock it down” and ship it as a fixed black box. It works, but you can’t inspect or modify it, much like proprietary software. This limits flexibility. Developers can’t easily adapt or build on top of it, and making small changes can require retraining from scratch. Yet this is a smaller issue when working with compact, well-trained policies designed for highly specific tasks, where the model’s scope is narrow and its behavior easier to characterize.
Deep reinforcement learning isn’t a silver bullet, but with the right tools and approach, it’s transforming robotics. Tasks that once seemed impossible to automate are now within reach. As we make these systems more efficient, reliable, and transparent, one thing is clear: the future belongs to modular, adaptive robotic software that empowers human developers to iterate quickly, leverage learning where it helps most, and build on top of existing knowledge.
That’s why the next generation of robotic platforms should be designed around flexibility: blending learning-based control, classical algorithms, and human-guided refinement so engineers can focus on solving problems, not rebuilding infrastructure.
AICA is a prime example of this much-needed new generation of robotic platforms. Our innovative framework seamlessly integrates deep reinforcement learning (RL), classical control, and learning from demonstration within a plug-and-play architecture that empowers engineers to build smarter, more adaptive systems. With AICA, every component, from force controllers to learned policies, can be integrated, replaced, or customized effortlessly, all operating within a robust event-driven logic.
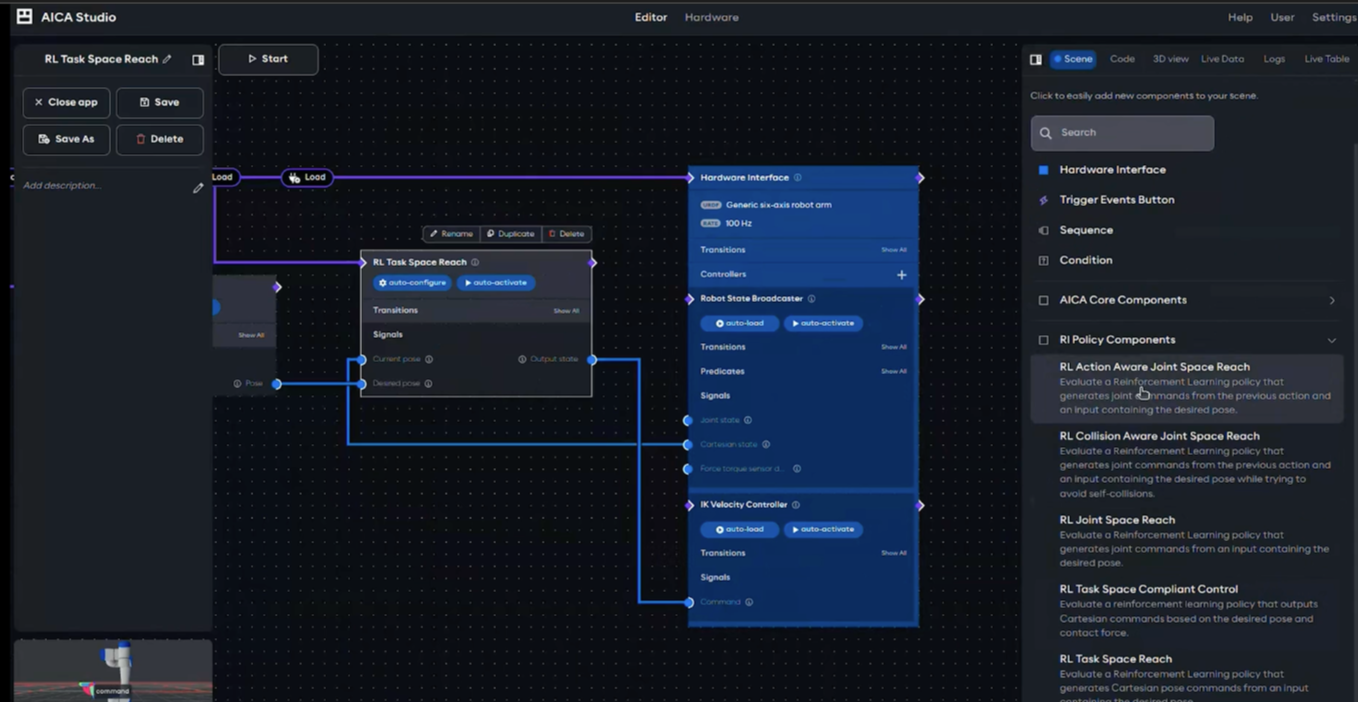
To make AI-driven control truly accessible, AICA developed a powerful Reinforcement Learning SDK. This SDK provides an end-to-end toolkit for creating, testing, and deploying your own RL components within the AICA System. It comes with ready-to-use libraries that simplify policy evaluation, state and action mapping, and evaluation on physics simulators. AICA’s actuator model learning pipeline further enhances realism by running applications on the actual robot, capturing actuator dynamics, and refining them in simulation for a minimized sim2real gap.
Additionally, our SDK tackles the “black box” challenge by giving developers the tools to fully understand and improve their models. It enables them to evaluate policies by running them in simulation and easily comparing their performance to alternative methods, interpret model behavior by building applications that reveal how a policy makes decisions before deployment, and fine-tune policies through a dedicated pipeline that supports efficient refinement in simulation prior to deployment on the real robot.
With these capabilities, AICA transforms RL policy deployment into a seamless experience, combining event-driven execution with valuable tools that bridge the sim-to-real gap. From concept to deployment, from model to motion, AICA is your one-stop platform to bring intelligent robotics to life, with just a few clicks.
Written by Yehya El-Hassan
Machine Learning Engineer
DISCOVER MORE ABOUT REINFORCEMENT LEARNING SDK
ABOUT REINFORCEMENT LEARNING SDK
Discover all the features of Reinforcement Learning SDK and how it fits your goals

Explore the use case about EV Battery disassembly on KUKA KR16
Gain a deeper understanding of Reinforcement Learning on AICAdemy, our free learning platform